SEO基礎觀念:認識檢索 (Crawl) 與索引 (Index)
檢索 (Crawl ) 與 索引 ( Index )是 SEO 領域裡面非常非常基本的兩個觀念,在學習 SEO 之前一定要理解,但檢索以及索引的優化概念很大,只透過一篇文章我可能沒有辦法完整的講完,因此這篇文章我只會針對基礎的概念先進行解說,並且在文章中連結到我曾經寫過的相關文章來幫助你學習 : )
Google 也有提供官方很多的 HTML 語法給網站經營者,透過這些語法以及 HTML 標記你可以優化搜尋引擎的爬蟲如何檢索、理解你的網站,不過每一種語法的功能不同,因此每一種語法我會以獨立的文章來撰寫,像是:
(重複內容文章內提到的Canonical標記便是一種常用到的SEO標記)
但在閱讀上述這些文章之前,建議還是必須要先看完這篇文章,確保自己已經有檢索 (Crawl )以及索引 (Index) 的概念。
理解SEO的『檢索』以及『索引』
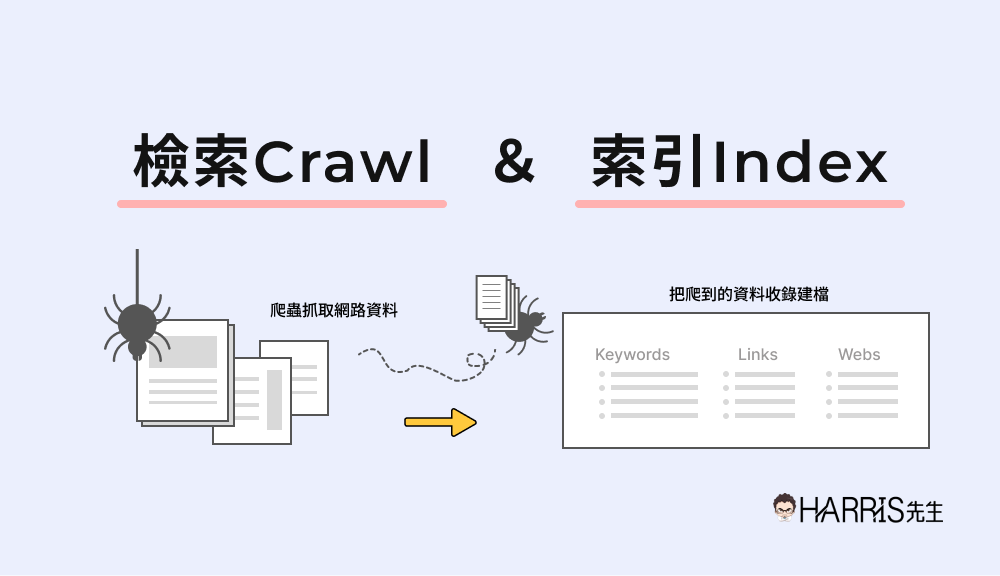
網路爬蟲這個說法比較抽象,Google 官方將它稱為 Google Spider、Google Bot,你可以把整個世界的網路想像為一個巨大蜘蛛網,而搜尋引擎本身有屬於它的一隻爬蟲程式,這支程式會像蜘蛛一樣在這巨大的網路上爬行,並收集資訊。
做 SEO工作,維持搜尋引擎爬蟲與網站之間良好的關係是非常重要的,我們必須要盡量讓它能夠完整爬取你網站上的優質內容,否則會對你的網站 SEO 有影響(在這篇文章中我會慢慢提到),而搜尋引擎運作原理我們可以簡單分為三個階段:
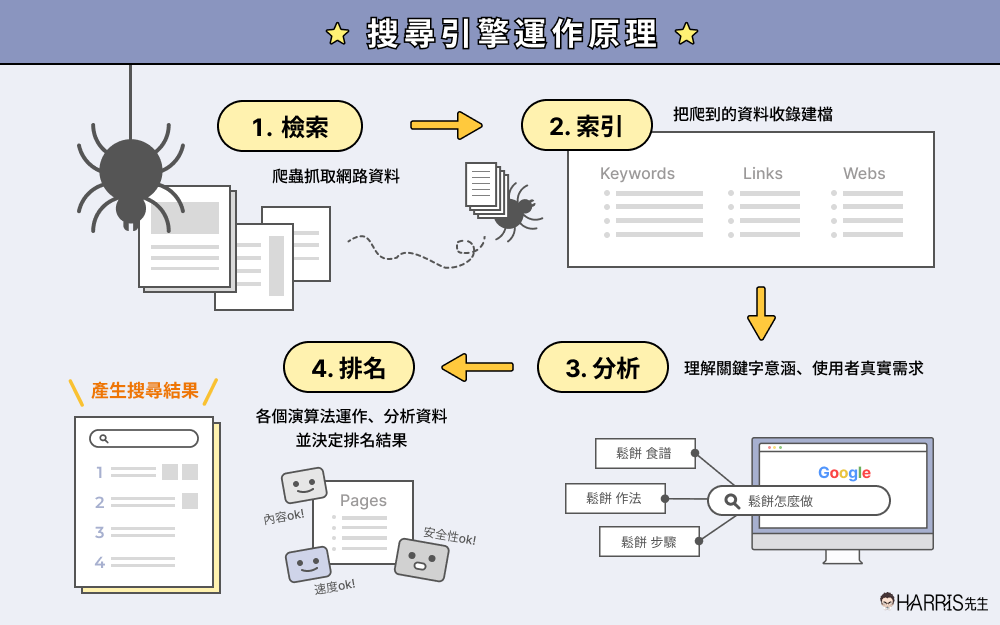
階段1 – 檢索 Crawl(爬取):搜尋引擎的爬蟲來你的網站上爬取、下載網站資料的這個動作我們叫做檢索,在 Google 官方的文件上正式的專有名詞叫做『檢索』,但 SEO 業界比較習慣白話一點來稱呼,通常我們會稱呼為爬取、抓取等比較白話的用詞。這個階段 Google 的爬蟲會在你的網站上爬取所有能爬到的資料,包含你的網頁內容、程式碼、圖片等所有的網頁資訊。
階段2 – 索引 Index(收錄):將你的網頁資料收錄、建檔到搜尋引擎裡面的這個動作我們叫做索引(白話一點來說就是收錄的意思),但你的網站就算被收錄到搜尋引擎裡面也不代表你會得到很可觀的搜尋流量,Google 也許願意收錄你的網站,但未必願意給你的網站很好的搜尋排名(取決於你的網站是否是一個優質的網站、是否有被很好的優化,否則 Google 也許願意收錄網站,但不願意讓你的網站很常被搜尋到)
很多人以為網站沒有搜尋流量就代表沒有被 Google 收錄,其實這觀念是不對的,『是否有被收錄』、『是否有排名有流量』是兩件事。但至少被 Google 收錄進搜尋引擎是好的第一步,如果 Google 連收錄你的網站都不願意,那更不用談搜尋流量以及SEO了。
階段3 – 分析搜尋意圖:Google 會透過演算法來了解使用者搜尋的「關鍵字」是什麼意思?使用者到底需要什麼資訊?
階段4 – 曝光在搜尋結果:搜尋者查詢關鍵字時,你的網站可能會被 Google 提供給搜尋者,而你的品牌也會因此獲得搜尋流量(但這取決於你的網站是否是一個優質的網站、是否有做SEO)。
為什麼學SEO要理解『檢索』以及『索引』?
實務上我們在學習 SEO 時,會碰到很多網路上的文章主題都是環繞在所謂的「排名因素」,也就是你的網站該怎麼做,才能被 Google 排名在搜尋結果的前面名次,但實務上一個網站會面臨到的 SEO 問題有很多面向,根據網站的架構、網站的產業、所在的市場等不同的因素而定,並不是只要優化「排名因素」就夠了,Google如果沒辦法很健康的爬取你的網站資料,那麼網站的排名因素優化做再好都沒用,因為 Google 爬蟲根本看不到你網站裡面的資料,所以你要了解搜尋引擎的爬蟲到底是怎麼檢索(爬取資料),然後又是怎麼索引(收錄)網站。
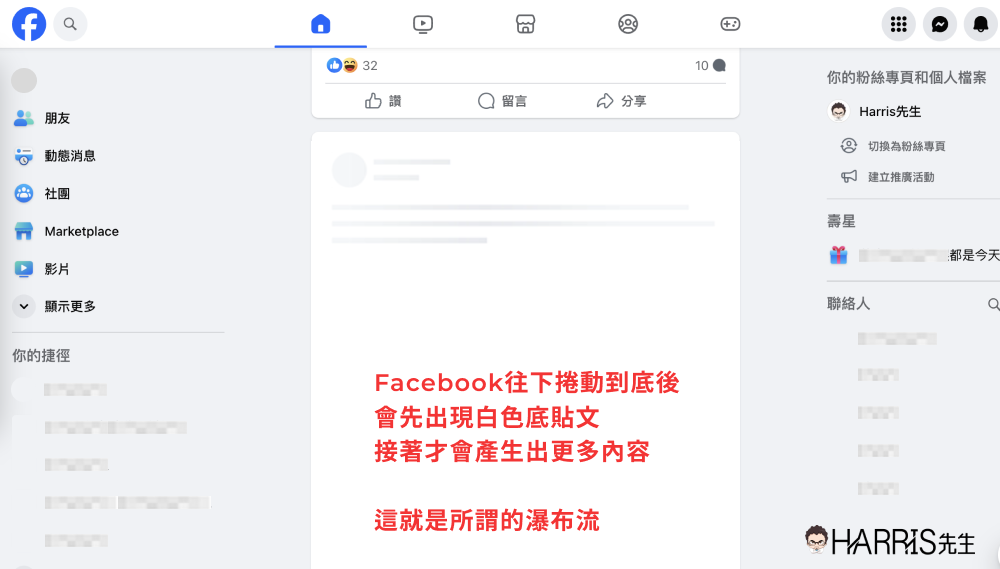
舉例來說,在我們實務上常常遇到有客戶的網站是使用 AJAX 程式建構出動態式的瀑布流,在你進入網站時會看到四則文章連結,接著你滑鼠向下捲動時,程式則會觸發並出現後面四則 (簡單來說就是 Facebook 現在的做法 ,俗稱瀑布流),
通常這個狀況底下,Google 爬蟲只會爬取到一開始的前面幾則文章而已,因為網路爬蟲不會像人類使用者去往下捲動、並觸發 AJAX 程式的瀑布流。在這類案例之下,Google 爬蟲看到的網頁資訊很少,當然也會影響你的 SEO(不管你的網站再棒、再好,只要 Google 爬蟲看不到,那麼根本沒有意義)。
因此做為 SEOer,研究、了解爬蟲的效能是很重要的,我們必須要了解搜尋引擎的爬蟲有哪些效能限制、哪些網頁技術是爬蟲無法好好的爬取(像瀑布流就是大多情況沒辦法被搜尋爬蟲很有效的爬到資料),而Google的爬蟲、Bing/Yahoo搜尋引擎的爬蟲又各自是不同的團隊/公司所開發出來,因此他們的爬蟲效能又有些不一樣,如果做 SEO 時希望除了 Google 之外的 Yahoo/Bing 也可以優化好,那麼就要全部都花時間去研究。
如何確定『檢索』或『索引』狀況是否有問題
這個議題有很多面向可以談論,在這篇我先談一些基礎觀念以及方法。
首先,大部分的情況只要你的網站被 Google 很健康的『爬取』,收錄狀況就不太會有問題,通常如果 Google 有很健康的檢索你的網站、但卻沒有收錄你的網站,那代表你的網站可能有違規、用作弊的方法做 SEO 而遭到 Google 懲處(除了違規懲處之外,很少有網站是檢索都沒問題,但 Google 卻不願意收錄你的網站)。
那麼,要如何檢查 Google 是否有健康的爬取(檢索)你的網站呢?常見的方法之一就是透過 Search Console 的報表(如下圖範例)。
(如果你還不知道甚麼是Search Console,可以參考這篇Search Console新手教學)
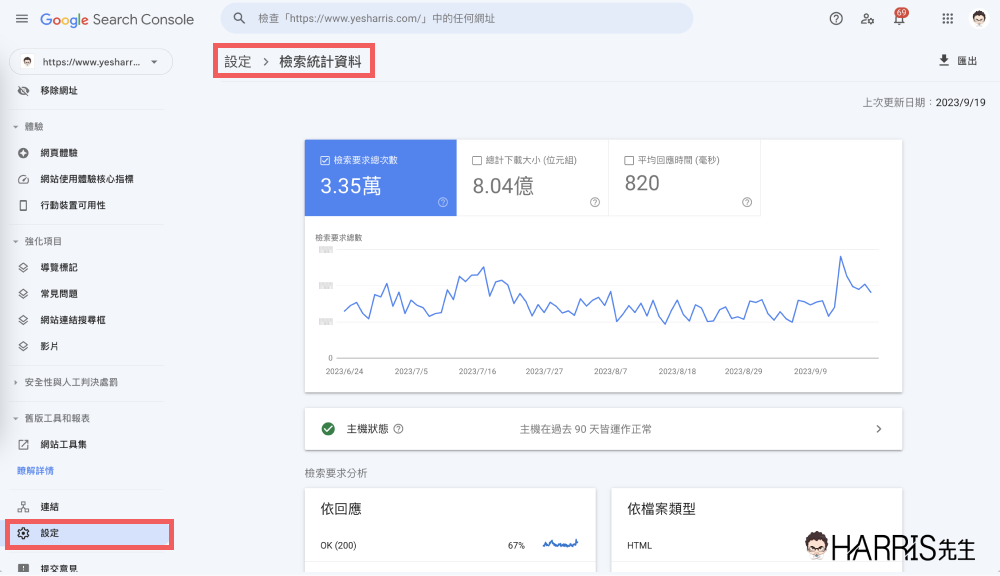
從 Search Console 的「設定>檢索統計資料報表」中,可以看到每日檢索的網頁數目,這張圖表代表著 Google 每天來爬你的網站時,都爬了多少個網頁,通常圖表會在一個區間範圍內波動,大多情況 Google 每天來爬多少網頁取決於三件事情:
- 你的網站在市場上有多重要、網站的SEO權重有多高(也就是所謂的Crawl Budget)
- 你的網站架構是否有使用不利於爬蟲的技術,導致爬蟲不容易爬到資料
- 你是否有主動阻擋Google爬你的網站(阻擋Google的部分可以閱讀非技術人員也能看懂的《meta robots、robots.txt》)
上述報表可以幫你檢查 Google 是否有健康的「爬取」你的網站,通常如果 Google爬你網頁的數字與你的網站落差太大,對 SEO 都是不太好的,比方說你的網站共有 8,000 個網頁,但 Google 每天來爬你的網站卻只有爬 50 頁~100 頁左右,如果你的網站有 8,000 頁,Google 每天爬的網頁數最好在 500~1,000 之間是比較正常的。
但「索引」呢?要如何檢查 Google 是否有健康的索引我的網站呢?
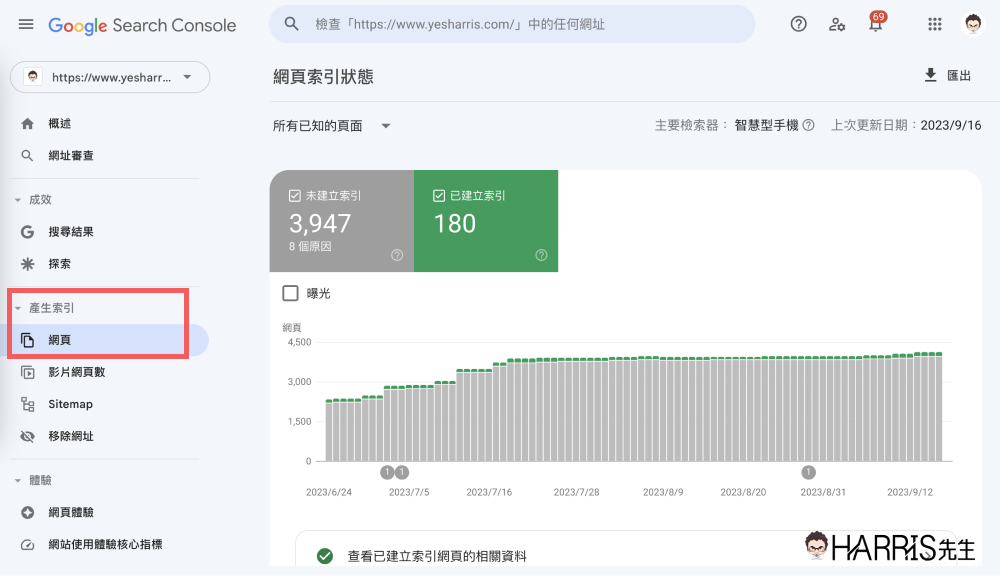
你可以從 Search Console 的網頁索引報表中,查看 Google 已建立索引的網頁數量,底下也會完整列出哪些網頁沒被編入索引、以及發生的原因。
這部分的詳細說明,可以閱讀這篇學習使用Site指令,診斷《 Google索引 》狀況,裡面有很完整的教學。
在SEO上要如何避免『檢索』以及『索引』出問題?
撇除你有違規、作弊的行為發生而導致 Google 不願意好好的處理你的網站,以下有幾個常見的優化項目,也是我們通常在擔任 SEO 顧問時會檢查的優化項目:
- 盡量不要過度使用對Google不友善的AJAX,尤其在重要的網頁或內容上面
雖然說 Google 近年來宣稱,搜尋引擎現在已經能夠滿有效的解析 JavaScript、AJAX 技術,但實務上還是有很多網站的 JavaScript、AJAX 沒辦法被 Google 很有效的解析(這篇文章中提到的瀑布流就是AJAX的一種應用),
因此盡可能避免在導覽列、麵包屑、網站側欄、商品/文章列表這些重要的地方使用JavaScript 以及 AJAX 會比較保險(在這篇文章我先列出幾個大方向的常見重點,未來我會在看大家回饋狀況各自拉出來寫成獨立的文章,JavaScript 與 AJAX 這個議題有太多層面要探討,但簡單總結的話就是不要太過度使用 AJAX)。
- 盡可能把『網站速度』優化好
根據Google官方的說明,Google 針對每一個網站有所謂的「爬取額度(Crawl Budget)」,也就是說他在爬你的網站時只會給予你一定的時間額度,因此你必須要盡可能的優化網站速度,讓爬蟲在最短的時間內可以爬到盡可能多的網站,而這個爬取的額度會根據你的網站在市場上的重要性、以及 SEO 的網站權重而定。
舉例來說,Google 決定給你的網站每天 10 分鐘的額度,那麼他每天只會來爬你的網站 10 分鐘,並且 10 分鐘一到他就會離開網站。因此,如果你的網站速度盡可能優化到好,可以幫助他在同樣的 10 分鐘內爬完你的網頁,概念上簡單來說是這樣:
當你的網站速度很慢時,他 10 分鐘只能爬完 100 個網頁。
當你的網站速度夠快時,他可以在 10 分鐘內爬完 500 頁。
以上述情況來說,你 SEO 成效的差距就出來了,我們會希望 Google 在同樣的時間內可以爬越多網頁越好,Google 如果連爬你的網站都不能好好的爬,基本上成效當然不好。
針對網站速度優化的部分,你可以參考這篇來獲得更多知識:超重要的 SEO 優化項目:『網站速度』優化
- 避免重複內容發生
重複內容問題要盡量避免(尤其是網址參數所產生的重複內容),重複內容會讓爬蟲要去爬更多無效的網頁(如果你不知道甚麼是重複內容,我在重複內容這篇文章有完整的解說),簡單來說,如果你的網頁總共有 500 頁,但你有很嚴重的重複內容問題而導致網頁膨脹到了 1,200 頁,那麼當中有 700 頁的網頁會浪費掉爬蟲的爬取額度,畢竟爬蟲每天能爬的網頁是很有限的。
- 最基礎的網頁問題以及SEO問題必須要避免
如果你有很多損毀/壞掉的網頁,或是網站上有很多不必要的、很胡亂的轉址可能都會影響爬蟲爬你網站的效能以及額度,因此在經營網站時一些最基礎的事情你必須要盡量避免,像是:
- 網頁盡量不要有損毀、壞掉的情況發生。
- 盡量避免不必要的轉址。
- 如果有產品/文章下架的話,請把連結從網站上移除,避免消耗掉你的爬取額度,同時,如果不妥善移除已下架的商品或文章,要是被使用者瀏覽到這些網頁對使用者的體驗也不是太好。
那麼今天這篇文章先寫到這囉,如果你們對這種比較技術性的知識有興趣,請讓我知道,我未來會多選一些這類型的題材,我們在其他文章上見囉 : )