robots.txt、meta robots設定:讓網頁不被Google搜尋到
上一篇文章我們介紹了搜尋引擎的運作原理:檢索(Crawl)與索引(Index)
今天我們要來介紹如何進一步優化 Google 對網站的檢索與索引,例如你有頁面不想出現在 Google 搜尋結果、或有測試中的頁面不想被 Google 爬到,這些情況透過 robots.txt、meta robots 就可以做好設定。
備註:這篇文章會大量提到「檢索」與「索引」的觀念,如果還不太了解的話一定要先閱讀上一篇文章喔!
這篇文章會由 Harris 先生顧問團隊維護、並且由 Harris 進行監修。
最後編修日期:2024 年 8 月
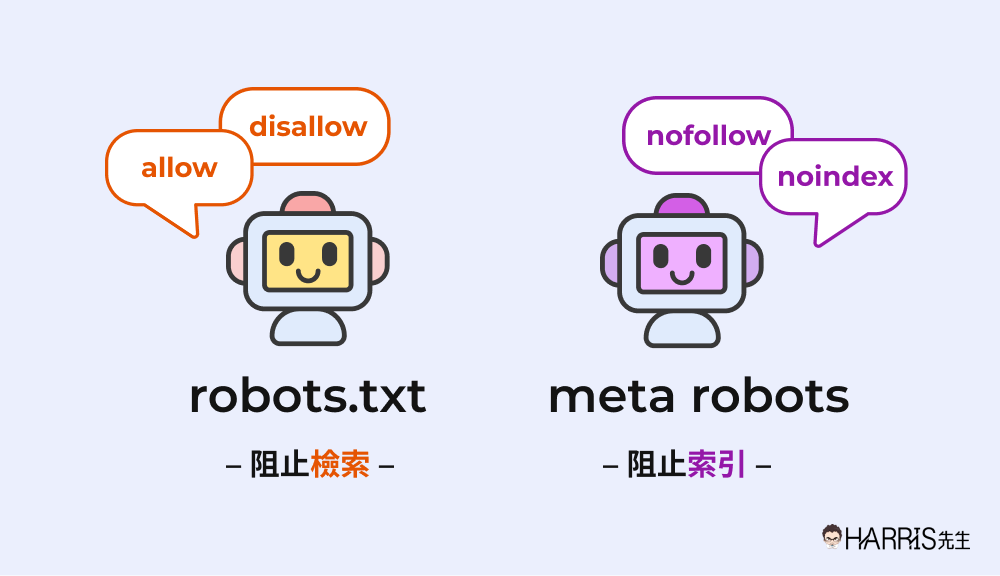
robots.txt 和 meta robots 是什麼?
robots.txt 以及 meta robots 的工作分別是阻止 Google 檢索/索引你的頁面。
網站中多多少少會有一些頁面,是不想要公開、不想被訪客看到的,例如測試頁面、文章草稿、登入頁面等等,出現在搜尋結果反而會傷害使用者體驗,這時就可以用 robots.txt/meta robots 來阻止頁面出現在 Google 搜尋結果。
| robots.txt | meta robots | |
|---|---|---|
| 功能 | 阻止 Google 檢索 (Crawl) | 阻止 Google 索引 (Index) |
| 使用方式 | 在 txt 文字檔案中列出要阻擋的頁面路徑,將檔案命成為 robots 並上傳到網站根目錄 | 於網站 Head 底下加入 meta robots 的標籤,例如 <meta name=”robots”content=”noindex, nofollow”> |
| 使用時機 | 有特殊頁面不希望被 Google 檢索,例如 – 測試用頁面 – 未完成頁面(文章草稿) | 有特殊頁面不想出現在搜尋結果,但這些頁面可能對 SEO 有幫助,所以還是讓 Google 進行檢索,例如: – 購物車 – 結帳頁面 |
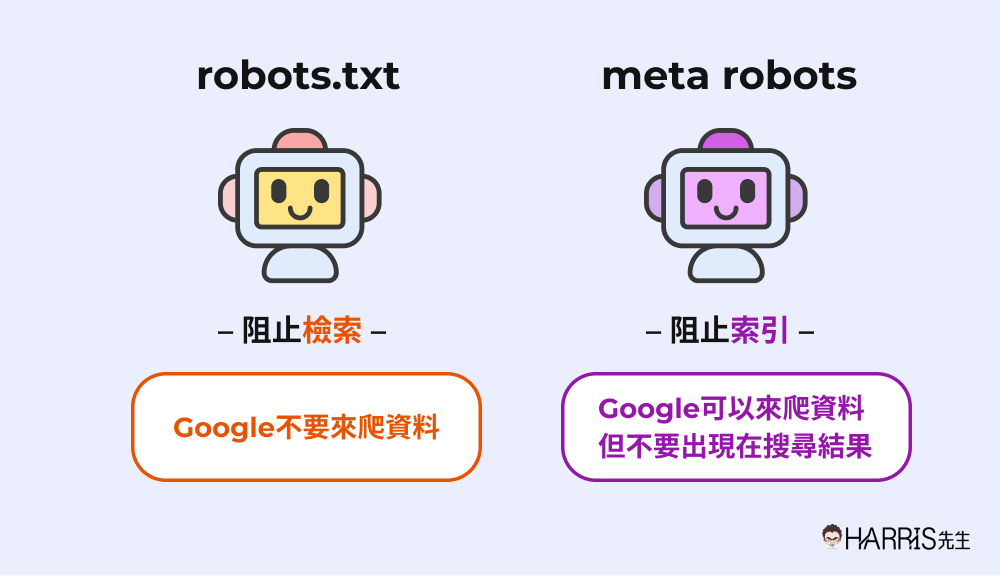
robots.txt 可以阻止搜尋引擎檢索資料,如果使用了 robots.txt 來阻擋搜尋引擎,那麼搜尋引擎將會略過我們所阻擋的頁面,不去做檢索。但 meta robots 就不同了,他只是阻止搜尋引擎索引頁面,但 Google 還是會來爬我們網站的資料。
robots.txt 和 meta robots 的功能和使用情境是完全不同的,接著我們會詳細介紹 robots.txt 和 meta robots 的設定方法、還有使用上的建議:)

想讓你的網站行銷更有效?我們可以幫忙
-
SEO優化:關鍵字進Google第一頁,讓顧客一搜尋就找到你
-
GA數據分析:用數據告訴你,網站哪裡有問題、又要怎麼改善
-
品牌行銷顧問:客製化制定行銷策略,真正提升商業表現
robots.txt 設定方法、使用時機
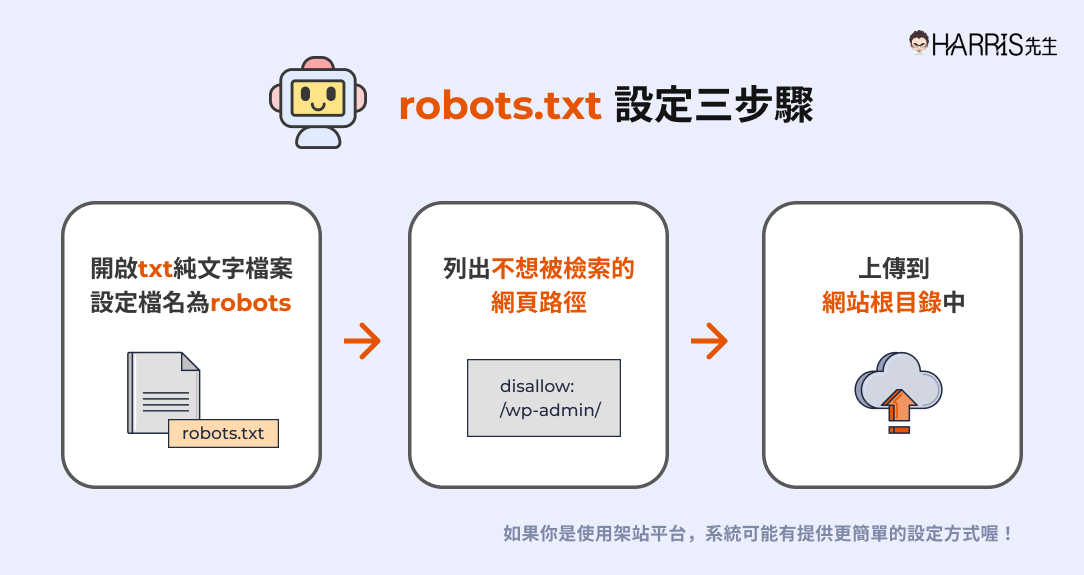
robots.txt 設定上很簡單,只要建立一個檔名為 robots 的 txt 純文字檔案,列出你不希望 Google 檢索的網頁路徑,然後上傳到網站根目錄就好。
基本上在 robots.txt 檔案內你需要填好這些資訊:
User-agent:填入搜尋引擎爬蟲的值(* 號代表全部)
Disallow:填入你不希望搜尋引擎檢索的頁面路徑
Allow:若你禁止檢索的頁面路徑裡面又有特定路徑你希望搜尋引擎檢索,則填入
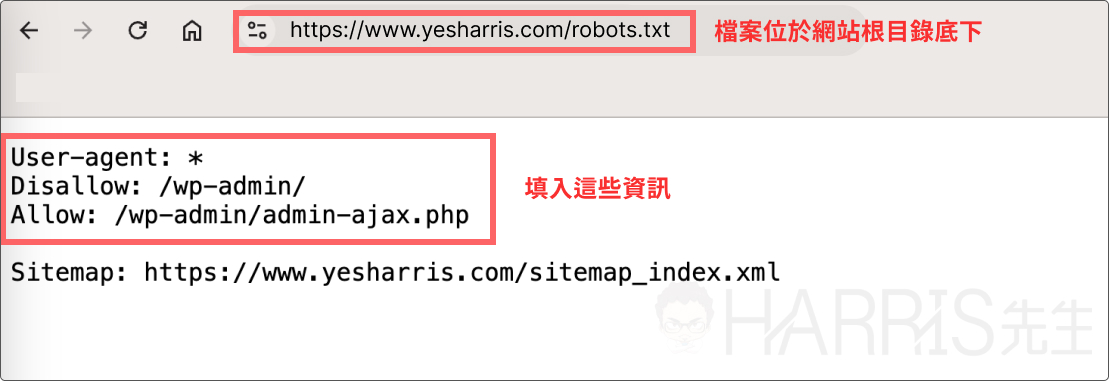
如上圖,在 Harris 官網 www.yesharris.com 根目錄底下可以看到這個 robots.txt 檔案,因為我們不希望搜尋引擎抓到官網後台的登入頁面,所以設定了 disallow:/wp-admin/
什麼時候會用到 robots.txt?
robots.txt 的主要功能是避免 Google 爬蟲檢索太多網頁而超出負荷,因為每一個網站都有所謂的「爬取額度(Crawl Budget)」,我們當然希望 Google 來爬取網站上重要的內容,而不是把額度拿去爬一些沒有 SEO 價值的網頁,例如測試頁面或網站後台。(換句話說,有 SEO 價值的網頁,我們都要讓 Google 盡可能地檢索)
所以在大多數的情況下,我們都不會使用 robots.txt 來阻止搜尋引擎檢索網站,如果你有頁面不希望出現在搜尋引擎中,建議使用 meta robots 來控制索引就好,網站的資料還是一樣讓 Google 去檢索會比較好。除非你確定這個頁面對 SEO 有負面影響、不希望被 Google 爬到,這時候再使用 robots.txt 來禁止檢索,例如這幾個情況:
- 未完成的頁面
如果網站上有還在開發、建置中的頁面,往往還需要很長一段時間的修改和測試才能正式上線,雖然未完成的頁面不會傷害 SEO,但我們不會希望訪客在 Google 搜尋到這些未完成的頁面、而影響了使用體驗,所以會用 robots.txt 暫時阻擋 Google 爬蟲來檢索。
- 測試頁面
有的工程師為了測試網站功能,會開一個測試用的子網域,並上傳與主網域完全一模一樣的內容,但是一模一樣的重複內容會對 SEO 造成傷害,若有這樣的頁面會建議將 Google 爬蟲擋在門外比較好。
- 網站後台、其他理由
以 Harris 官網為例,我們有使用 robots.txt 來防止搜尋引擎檢索網站後台,雖然搜尋引擎檢索到後台的登入頁面對於 SEO 不會有傷害,但沒有幫助也沒有必要。
如果你網站有特殊需求,例如不希望 Google 檢索圖片、不希望檢索整個網站,也可以使用 robots.txt 來告訴搜尋引擎,常見的 robots.txt 格式可以參考官方說明文件。
meta robots 設定方法、使用時機
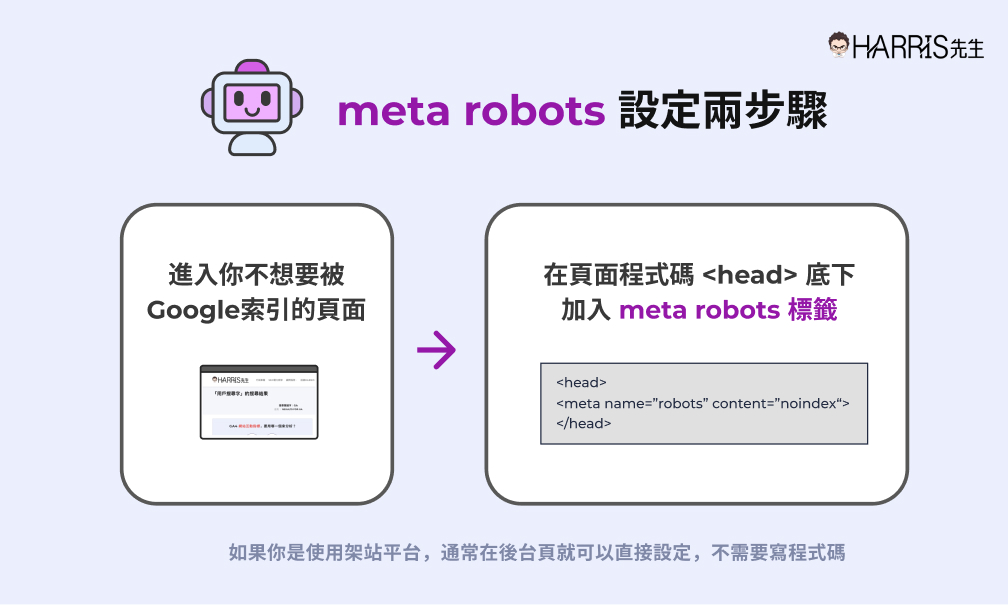
接著我們來認識比較常用到的 meta robots。meta robots 的設定方法是在「你不希望被 Google 索引的頁面」的 head 底下,加入 meta robots 的標籤,例如:
<head>
<meta name=”robots” content=”noindex , nofollow“>
</head>
meta name=”robots”是指將這個規則套用到所有的 Google 檢索器中
而 content= 的部分你可以自行填入「對於此頁面的規範標籤」,例如 noindex 禁止索引、nofollow 禁止追蹤連結、nosnippet 禁止顯示精選摘要……等等,有十幾種標籤可以自行設定。這邊介紹最普遍、做 SEO 一定要認識的 noindex 與 nofollow:
【noindex】
noindex 是禁止索引的意思,如果不希望這個頁面出現在搜尋結果,就填上 noindex
【nofollow】
nofollow 是指請 Google 不要追蹤這個頁面上所連出去的連結。搜尋引擎的運作是沿著連結前進的,但設定 nofollow 後,搜尋引擎就會在這個頁面停止,不繼續爬其他連結。通常社群論壇或是網站討論版都會設定 nofollow,防止有人在網站上亂貼連結以增加他的 SEO 反向連結及排名,
蠻多人會混淆 noindex 和 nofollow 的用途,我們來用幾個範例進一步說明:
1. < meta name=”robots” content=” noindex , nofollow”>
這個做法便是告訴搜尋引擎,這個頁面不要出現在搜尋結果(禁止索引),也不要去爬這個頁面上的連結。
2. < meta name=”robots” content=”index , nofollow”>
這個頁面可以出現在搜尋結果,但請 Google 不要去爬頁面上的連結。
(這是社群論壇常見做法,可以防止大家亂貼連結造成網站權重分散)
3. < meta name=”robots” content=” noindex, follow”>
這個頁面不要出現在搜尋結果(禁止索引),但頁面上所有的連結請都可以正常檢索。(一般最常用的做法)
4. < meta name=”robots” content=”index , follow”>
這個做法就沒有任何意義,因為系統預設就是 index 與 follow,加上這段標籤跟沒加的道理是一樣的,等於請搜尋引擎正常索引及檢索。
什麼時候會用到 meta robots?
若某些頁面你不希望出現在 Google 搜尋結果,但這些頁面又對 SEO 排名有加分的話,這時就建議使用 meta robots 來告訴搜尋引擎:希望 Google 爬蟲檢索這些頁面,但不要索引進入搜尋引擎。
這種情況通常是因為某些頁面作為 Landing Page 會影響使用者體驗,但你又希望 Google 能檢索頁面上的資料(因為這頁有很多的反向連結和流量),所以你將它維持檢索、排除索引。舉例來說:
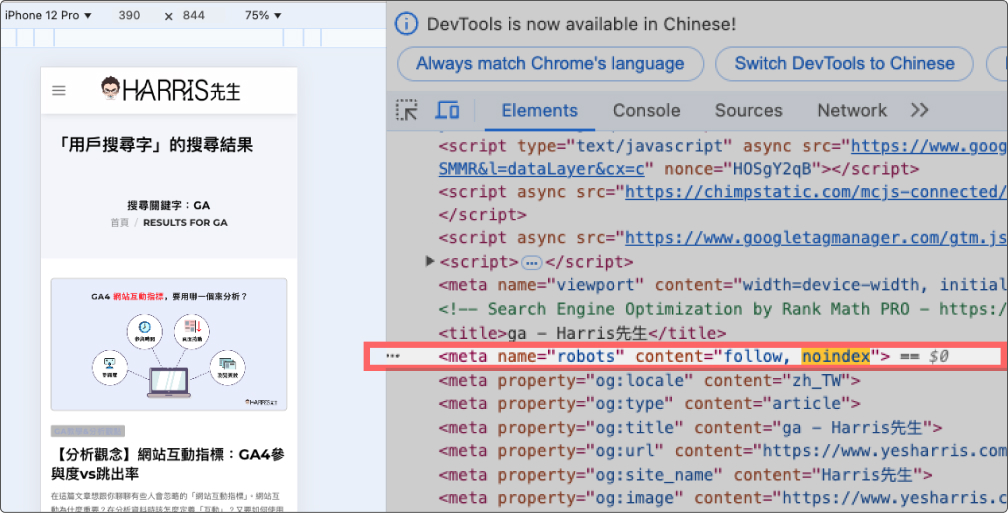
以上圖為例,Harris 官網部落格的「站內搜尋結果頁」上使用了 meta robots 的 noindex 來阻止 Google 索引。因為若新訪客從 Google 搜尋進到舊訪客的「站內搜尋結果頁」,這樣會對新訪客造成不佳的使用體驗;但同時我們的「站內搜尋結果頁」又有很多反向連結和流量,這些對網站 SEO 排名有幫助,我們還是希望 Google 能來檢索這個頁面,這時就可以使用 meta robots 來禁止 Google 索引,不過 Google 還是可以爬到這頁的資料、並且頁面上所有的連結都可以正常檢索。
除了站內搜尋頁面之外,通常電商網站的購物車、結帳頁面也會設定 meta robots noindex 禁止索引,避免這些頁面出現在搜尋結果中。
注意事項提醒
最後有幾個 robots.txt 和 meta robots 的注意事項和要分享給你:
1. robots.txt 是在檔案中一次列出你想禁止檢索的路徑,而 meta robots 則是在你想禁止索引的頁面中單獨做設定。所以若你有 10 個頁面不想被索引,就要手動在這 10 個頁面都加入 meta robots。
2. 如果你的網站是使用 WordPress、Wix、或是電商平台架設的,通常可以在後台頁面設定中找到 noindex、nofollow 的選項,不需要修改 HTML 程式碼就可以做好 meta robots 的設定。
3. Google 官方有很明確的聲明,robots.txt 與 meta robots 確實可以告訴搜尋引擎你希望哪些頁面不要被檢索及索引,Google 也會尊重你的決定(畢竟你是網站擁有者),但 Google 官方不保證搜尋引擎會完全服從 robots.txt 與 meta robots 的設定,若搜尋引擎認為你的網站是優質網站,有很多很多的流量、反向連結、優質內容,他也有可能會執意要檢索、索引你的網站。